You might remember year 2k for Bill Gates stepping down as CEO (and promoting Steve Balmer), American Beauty winning 5 Oscars, liberation of Lebanon after 22 years of Israeli occupation, end of RSA patent, Bill Clinton becoming the first U.S. president to visit Vietnam, and I will certainly remember it for the Bulldozer Revolution in my country which lead to the resignation of Slobodan Milošević.
 That year marks a big milestone in the world of software engineering: in a conference keynote, prof. Eric Brewer postulated the now famous and much discussed CAP theorem (btw it was proven 2 years later by Gilbert and Lynch), and paved the way for the NoSQL revolution.
That year marks a big milestone in the world of software engineering: in a conference keynote, prof. Eric Brewer postulated the now famous and much discussed CAP theorem (btw it was proven 2 years later by Gilbert and Lynch), and paved the way for the NoSQL revolution.
Another big factor for NoSQL was getting away from the relational model (proposed way back in 1969) and ACID to achieve scale, performance. Having felt the pain of working with object-relational mappers, developing a webapp on MongoDB for the first time was such a pleasant experience.
Unfortunately (most of) the current NoSQL systems (read MongoDB, Riak, Cassandra, …) force developers to deal with messy aspects of consistency, concurrency, non-zero latencies, weird corner cases of failure scenarios, not to mention designing CRDTs, or asking some philosophical questions like how-eventual-is-eventual-consistency (there’re some promising developments like Google’s Spanner and HyperDex, but haven’t had time to have a look).
I’ve successfully managed to avoid dealing with these thorny issues for a few years now, but this fantastic series of articles called Jepsen by Kyle Kingsbury got me motivated to address these using CouchBase. His series of articles is not only eye-opening from the developer’s point of view, but it also reveals some shocking discoveries, namely some databases claim things they don’t provide (Redis being a CP system, MongoDB being safe, etc).
I’m not smart enough to prove that a database is broken by design, and even if I was it would require more time than I afford to invest, so Kyle’s experimental approach is the preferred way. Since I don’t speak Clojure, the implementation language of his choice for Jepsen, this will be done in Java (yeah, I know, it’s not that cool anymore, but it gets the job done).
Cluster setup
The first cluster setup was just like Kyle’s using LXC, but I ran into some networking issues, one node would just deny connection attempts, so I ended up using 5 VMs on my Mac laptop.
For a detailed explanation of what and how this test is supposed to work have a look at http://aphyr.com/posts/281-call-me-maybe-carly-rae-jepsen-and-the-perils-of-network-partitions. Here’s a quick recap:
A five node cluster of Ubuntu 14.04 machines, running in VMs (VmWare or VirtualBox). VMs – 192.168.1.131 – 192.168.1.135 (named n1-n5 – add these entries to /etc/hosts on your computer and on each of the nodes themselves).
To cause a partition, Kyle makes “nodes n1 and n2 to drop IP traffic from n3, n4, and n5–essentially by running”:
iptables -A INPUT -s n3 -j DROP iptables -A INPUT -s n4 -j DROP iptables -A INPUT -s n5 -j DROP
In my experiments, I wanted to have ssh access all the time on all VMs so I drop a port range that covers all CouchBase ports (they should be above 1024), like this:
iptables -A INPUT -p tcp --dport 200:65535 -j DROP
To resolve the partition, we’ll reset iptables chains to their defaults:
iptables -F
A client will be a simple app that appends integers to a single document – read & append number & use cas to update, and record if the db acknowledged the write or there was an error. At the end I’ll compare if the db and client apps agree on the state, or acknowledged writes are missing and/or unacknowledged writes are present.
A simple time-out test first
Before going with the full cluster, let’s test the code against a single node cluster running CouchBase 2.5.1: 256MB ram; default bucket is type Couchbase, 256MB ram quota, 0 replicas, 2 workers, flush enabled.
The client app will use Java SDK 1.4.3 and Oracle JDK 1.7.0_55.
CouchTimeoutTest first opens a connection to CouchBase – CouchbaseClient with the OP timeout of 10sec, sets an empty JSON document with a single array element, appends 50 numbers to the array, then makes the node drop all traffic for CouchBase ports, and tries to add 150 more elements to the array:
public void run() {
cluster.getHealthy();
setEmptyDocument();
appendToDocument(50);
cluster.uniDirectionalPartition();
cluster.scheduleHealAndShutdownIn(15);
//sleep while the node recovers?
appendToDocument(150);
client.shutdown();
log.info("DONE!");
}
All operations are synchronous. The Java SDK driver docs describe how to deal with time-outs: “When a time-out occurs, most of the synchronous methods on the client return a RuntimeException showing a time-out as the root cause.”, so the appendToDocument implementation looks like this:
String addElementToArray(Integer nextVal, int numAttempts) {
long start = System.currentTimeMillis();
for (int i = 0; i < numAttempts; i++) {
CASValue<Object> casValue = client.gets(key);
String updatedValue = appendElement(casValue.getValue().toString(), nextVal);
try {
final CASResponse casResponse = client.cas(key, casValue.getCas(), updatedValue);
switch (casResponse) {
case OK:
log.info("added " + nextVal + " in " + (System.currentTimeMillis() - start));
return updatedValue;
case EXISTS:
log.debug("retrying " + nextVal);
break;
default:
log.error("error trying to add " + nextVal + ": " + casResponse);
return null;
}
} catch (IllegalStateException ex) {
log.warn("outpacing the network, backing off: " + ex);
try {
Thread.currentThread().sleep(1000 * random.nextInt(5));
} catch (InterruptedException e) {
log.warn("interrupted while sleeping, failed to add " + nextVal, e);
Thread.currentThread().interrupt();
return null;
}
} catch (RuntimeException ex) {
if (ex.getCause() instanceof TimeoutException) {
log.error("timed out adding " + nextVal);
} else {
log.error("error adding " + nextVal, ex);
return null;
}
}
}
log.error("failed to append " + nextVal + " in " + numAttempts + " attempts");
return null;
}
Test result
The client is configured to timeout after 10sec, and the partition lasts for 15s so I expect to see some timeouts and retries. In the end the document should have 200 integers in the array. Manually checking the iptables rules I see the code correctly heals the node. What do you think happened when I ran this code (using maven exec plugin, mvn test -Pcouch-timeout)?
- a few operations timed out and then succeeded
- a few operations timed out and then failed
- CouchbaseClient failed to reconnect so only 50 integers were written
- an infinite loop
Believe it or not it’s the 4th option. CouchbaseClient never timeouts or throws anything, just keeps running forever broadcasting noops to probably keep the connection alive:
2014-07-22 19:27:52,342 DEBUG [com.couchbase.client.CouchbaseConnection] - Handling IO for: sun.nio.ch.SelectionKeyImpl@208ee9c9 (r=true, w=false, c=false, op={QA sa=dimsplatform.com/192.168.1.128:11210, #Rops=1, #Wops=0, #iq=0, topRop=Cmd: 10 Opaque: 354, topWop=null, toWrite=0, interested=1})
2014-07-22 19:27:52,342 DEBUG [com.couchbase.client.CouchbaseConnection] - Read 24 bytes
2014-07-22 19:27:52,342 DEBUG [com.couchbase.client.CouchbaseConnection] - Completed read op: Cmd: 10 Opaque: 354 and giving the next 0 bytes
2014-07-22 19:27:52,342 DEBUG [com.couchbase.client.CouchbaseConnection] - Done dealing with queue.
The cluster is healthy, node up and running; if I spin another client it reads/writes without any problems.
What happens if the server is unavailable for some amount of time less than the configured timeout (10sec in this test)? The magic number seems to be 7, for anything longer the test deadlocks.
The SDK docs are pretty clear in that “when a time-out occurs, most of the synchronous methods on the client return a RuntimeException“.
It turned out (thanks Michael) the problem was the test code – getting the doc was outside any try/catch and somehow the exceptions were getting swallowed (not even showing in the log?!). The fix is:
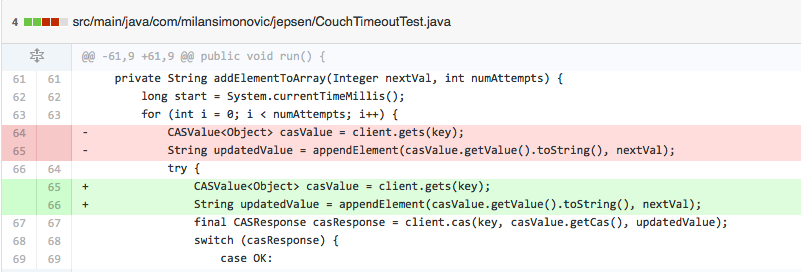
With this change, the test runs as expected, a few ops time out but eventually all succeed:
... 2014-08-25 11:52:04,749 INFO [com.milansimonovic.jepsen.CouchTimeoutTest] - added 49 in 1 2014-08-25 11:52:04,750 INFO [com.milansimonovic.jepsen.CouchTimeoutTest] - added 50 in 1 2014-08-25 11:52:04,750 INFO [com.milansimonovic.jepsen.Cluster] - creating 1 way partition 2014-08-25 11:52:05,753 INFO [com.milansimonovic.jepsen.Cluster] - creating partition DONE 2014-08-25 11:52:05,753 INFO [com.milansimonovic.jepsen.Cluster] - scheduled heal in 15 seconds 2014-08-25 11:52:15,755 ERROR [com.milansimonovic.jepsen.CouchTimeoutTest] - timed out adding 51 2014-08-25 11:52:20,754 INFO [com.milansimonovic.jepsen.Cluster] - healing partition 2014-08-25 11:52:21,757 INFO [com.milansimonovic.jepsen.Cluster] - healing partition - DONE 2014-08-25 11:52:21,757 INFO [com.milansimonovic.jepsen.Cluster] - closing connections 2014-08-25 11:52:25,758 ERROR [com.milansimonovic.jepsen.CouchTimeoutTest] - timed out adding 51 2014-08-25 11:52:26,667 INFO [com.milansimonovic.jepsen.CouchTimeoutTest] - added 51 in 21035 2014-08-25 11:52:26,669 INFO [com.milansimonovic.jepsen.CouchTimeoutTest] - added 52 in 2 ... 2014-08-25 11:52:27,072 INFO [com.milansimonovic.jepsen.CouchTimeoutTest] - added 200 in 1 2014-08-25 11:52:27,073 INFO [com.couchbase.client.CouchbaseConnection] - Shut down Couchbase client 2014-08-25 11:52:27,074 INFO [com.couchbase.client.ViewConnection] - I/O reactor terminated 2014-08-25 11:52:27,074 INFO [com.milansimonovic.jepsen.CouchTimeoutTest] - DONE!
The next article will explore how CouchBase behaves when this test runs against a 5 node cluster.
Hi,
can you share your builder configuration? You said its configured for 10 seconds but on gets / cas you use the default timeout which is set to 2.5s if not overriden.
Also, it’s not clear from the article: did you just run it against a healthy cluster or did you already induce the partition?
Thanks,
Michael
you mean this (timeoutMillis is 10000):
builder.setOpTimeout(timeoutMillis);//2.5 by default
builder.setObsTimeout(timeoutMillis);
https://github.com/mbsimonovic/jepsen-couchbase/blob/master/src/main/java/com/milansimonovic/jepsen/CouchbaseClientFactory.java#L33
I start the test by writing to a healthy 1-node cluster, and after 50 writes, make the node drop all packets for 15sec.
thanks,
and at which point exactly does the infinite loop show up? when you start dropping the packets? After how many seconds do you reset the firewall?
1. open CouchbaseClient with opTimeout = 10sec
2. write 50 docs (works fine)
3. make the server drop packets for 15sec
4. try to write another doc -> blocks forever
trying different timeout values: opTimeout =2.5sec, drop packets for 5sec, but it also never times-out
you mean this (timeoutMillis is 10000):
builder.setOpTimeout(timeoutMillis);//2.5 by default
builder.setObsTimeout(timeoutMillis);
https://github.com/mbsimonovic/jepsen-couchbase/blob/master/src/main/java/com/milansimonovic/jepsen/CouchbaseClientFactory.java#L33
I start the test by writing to a healthy 1-node cluster, and after 50 writes, make the node drop all packets for 15sec.
First off, thanks for filing the issue and I’m sure we’ll work to repro it soon. I can’t immediately think of a reason you’d not get an exception back. It’ll be interesting to look at a thread dump in that state when we repro.
As the guy who opened SPY-30, note there that I mention the continuous operation timeout. That is a heuristic which relies on (IIRC) 1000 continuous timeouts to a given node. While that sounds kind of high, it was from an Open Source contribution by a guy who runs it at a large site and we usually see thousands of ops/s. It’s tune-able though.
The interesting thing is the timeout under the synchronous operation is based on a java.util.concurrent latch. My suspicion is that this is exposing some un-handled error situation on the async IO thread. Even if that does happen though, how could that break java.util.concurrent’s latch? Your thread is really just creating objects, putting them on queues and waiting on latches.
One suspicion, and I’ll try to read the code more carefully here, but you’re doing lots of retries with 10s timeouts and with synchronous failures and retries, it may just be that it’s spending a long time waiting between iterations. But, no log output. We’ll figure it out pretty quickly I’m sure.
just one remark: it also happens with 2.5sec timeouts
I think I found a bug in your code while running the sample. It’s good stuff btw! But you forgot to also move the gets call into the try/catch and since it can also time out the exception gets swallowed somewhere and your executing thread dies.
With my PR things go through nicely: https://github.com/mbsimonovic/jepsen-couchbase/pull/2
Hi Milan,
Your article/test is as same as interesting as Kyle Kingsbury’s. Thanks for the sharing.
Did you proceed to test against a 5 node couchbase cluster? I am curious what’s the result.