
Abstract
In this post I’ll tell you about installing and using CouchBase in a test-first manner. Wiping out all the data between tests turned out to be very slow – 4s per test [MB-7965], and for anything but key lookups indexes have to be used, so the elephant is still in the room. CouchBase’s async nature makes setting up testing infrastructure a bit more difficult compared to MongoDB or relational databases.
Motivation
I’ve used MongoDB for a couple of projects at work (http://pax-db.org); it’s great for read-only data, logs and analytics.
It turned out to be rather difficult to operate (puppetize, coordinating replicasets initialization, watching oplog, …); consistent hashing over a set of equal nodes sounds like it’s more likely to work reliably than async master-slave (plus seems more efficient – mongo secondaries are not used to serve content); sharding+replica sets is way more painful than elastically growing (and shrinking!) a dynamo-like system; plus mongodb can and will lose data (under network partitions).
The document model seems like a good fit, so what’s else out there, and doesn’t suck: CouchBase.
Installing CouchBase
In a virtual box (IP 192.168.1.128), just in case…
$ wget couchbase*.deb # The docs says dependencies have to be installed manually first, and lists only one, libssl, but trying to install on a vanilla ubuntu 14 box doesn’t agree: sudo dpkg -i couchbase-server-enterprise_2.5.1_x86_64.deb #librtmp0 missing.. $ sudo dpkg -I couchbase-server-community_2.2.0_x86_64.deb new debian package, version 2.0. size 137295996 bytes: control archive=154416 bytes. 624 bytes, 15 lines control 562481 bytes, 5579 lines md5sums 3100 bytes, 103 lines * postinst #!/bin/sh 171 bytes, 7 lines * postrm #!/bin/sh 2737 bytes, 112 lines * preinst #!/bin/sh 526 bytes, 11 lines * prerm #!/bin/sh Package: couchbase-server Version: 2.2.0 Architecture: amd64 Maintainer: Couchbase <[email protected]> Installed-Size: 402664 Depends: libc6 (>= 2.15), libgcc1 (>= 1:4.1.1), libreadline6 (>= 6.0), librtmp0 (>= 2.3), libssl1.0.0 (>= 1.0.0), libstdc++6 (>= 4.6), libtinfo5, zlib1g (>= 1:1.1.4), lsb-base (>= 3.2) Breaks: membase-server Replaces: membase-server Section: web Priority: extra Homepage: http://couchbase.com Description: Couchbase Server Couchbase Server is the leading distribution of memcached and couchbase, created and supported by top contributors to the memcached and couchbase open source projects. $ sudo dpkg -i couchbase-server-enterprise_2.5.1_x86_64.deb Selecting previously unselected package couchbase-server. (Reading database ... 106095 files and directories currently installed.) Preparing to unpack couchbase-server-enterprise_2.5.1_x86_64.deb ... libssl1* is installed. Continue installing Minimum RAM required : 4 GB System RAM configured : 2042696 kB Minimum number of processors required : 4 cores Number of processors on the system : 2 cores Unpacking couchbase-server (2.5.1) ... Setting up couchbase-server (2.5.1) ... * Started couchbase-server You have successfully installed Couchbase Server. Please browse to http://demo:8091/ to configure your server. Please refer to http://couchbase.com for additional resources. Please note that you have to update your firewall configuration to allow connections to the following ports: 11211, 11210, 11209, 4369, 8091, 8092, 18091, 18092, 11214, 11215 and from 21100 to 21299. By using this software you agree to the End User License Agreement. See /opt/couchbase/LICENSE.txt. Processing triggers for ureadahead (0.100.0-16) ... ureadahead will be reprofiled on next reboot
Setup
(mental note: think about puppet-izing ..)
Why do I have to create a default bucket!?
The upcoming Java SDK v2.0 looks very neat, reactive and async, with Java 8 lambdas, but until then need to stick with the latest stable v1.4.2 now.
Using Oracle jdk1.7.0_55.jdk on Mac OS X Mavericks.
Test first
Hello couchbase in java works fine. Encouraging, let’s try to implement a CRUD for a simple class (having a few primitive fields). Spring-data already can provide this but before automating something it’s usually a good idea to do it manually first. Plus spring-data mongodb hurt me once, but more on that in another post.
It starts with a test of course. Need to open a client first (hm, is CouchbaseClient thread-safe, has it got connection pooling under the hood, … the API docs don’t say anything, but the executorService field suggests it does have pooling; mental note: read the source code..). Docs v2.0 say Java SDK is thread safe (the C lib is not): “Couchbase Java and.Net SDKs have been certified as being thread-safe if you utilize thread-safety mechanisms provided by the two languages with the SDKs”. Alright, I can now sleep peacefully.
The documentation is somewhat confusing, http://docs.couchbase.com/, some sections only exist in 2.0, others in 2.1…
For example: thread-safety in sdk exists in v2.0, but not in v2.1 and v2.2. Wish there was a PDF version…
Back to the unit test, open a client in @BeforeClass, lets use a test bucket, so I don’t by mistake mess up the production data. To have tests isolated and repeatable (as defined in F.I.R.S.T), lets create/delete bucket before each test, using ClusterManager#createNamedBucket (introduced in v1.1), and run the test:
@BeforeClass
public static void setUpBefore() throws Exception {
clusterManager = new ClusterManager(Arrays.asList(URI.create(COUCH_SERVER)), admin, adminPass);
clusterManager.createNamedBucket(BucketType.COUCHBASE, TEST_BUCKET, 100, 0, PASSWD, true);
client = new CouchbaseClient(Arrays.asList(URI.create(COUCH_SERVER)), TEST_BUCKET, PASSWD);
}
creating the CouchbaseClient on the 5th line throws an exception:
com.couchbase.client.vbucket.config.ConfigParsingException: Number of vBuckets must be a power of two, > 0 and <= 65536 (got 0)
A forum thread says it’s probably a timing issue, couch is still not done creating the bucket. The mentioned links to BucketTool.java and ViewTest.java are 404s, so lets ask my friend git:
$ git log --oneline -5 -- src/test/java/com/couchbase/client/BucketTool.java ec02294 Migrating Codebase. 95569c4 Fix ClusterManager too optimistic timeouts. 3617768 JCBC-280 - Support for edit bucket functionality through cbc. 5d283c2 Happy 2013! 9d948c7 Renamed the bucket create method to abstract type better.
Removed in ec02294, let’s go one rev before that one – 95569c4: BucketTool.java, ViewTest.java. The code looks like mine, creating a (default) bucket first then calling initClient. A dead end.
One of the blog posts mentioned something about setting timeouts, lets see:
@BeforeClass
public static void setUpBefore() throws Exception {
clusterManager = new ClusterManager(Arrays.asList(URI.create(COUCH_SERVER)), admin, adminPass);
clusterManager.createNamedBucket(BucketType.COUCHBASE, TEST_BUCKET, 100, 0, PASSWD, true);
CouchbaseConnectionFactoryBuilder factoryBuilder = new CouchbaseConnectionFactoryBuilder().setObsTimeout(15000); //2.5sec by default
CouchbaseConnectionFactory cf = factoryBuilder.buildCouchbaseConnection(Arrays.asList(URI.create(COUCH_SERVER)), TEST_BUCKET, PASSWD);
client = new CouchbaseClient(cf);
}
Nope, still the same error. Going through the couch docs, I noticed the cli tool has an option to wait:
--waitWait for bucket create to be complete before returning
Hm, wonder how is that implemented..
# Make sure the bucket exists before querying its status
bucket_exist=False
while(time.time()-start)<=timeout_in_secondsandnotbucket_exist:
buckets=rest_query.restCmd('GET',rest_cmds['bucket-list'],
self.user,self.password,opts)
for bucket in rest_query.getJson(buckets):
if bucket["name"]==bucketname:
bucket_exist=True
break
if not bucket_exist:
sys.stderr.write(".")
time.sleep(2)
Pooling bucket-list until it’s created. Seems like there’s no other way but to sleep:
@BeforeClass
public static void setUpBefore() throws Exception {
clusterManager = new ClusterManager(Arrays.asList(URI.create(COUCH_SERVER)), admin, adminPass);
clusterManager.createNamedBucket(BucketType.COUCHBASE, TEST_BUCKET, 100, 0, PASSWD, true);
Thread.sleep(500);
client = new CouchbaseClient(Arrays.asList(URI.create(COUCH_SERVER)), TEST_BUCKET, PASSWD);
}
@org.junit.Test
public void testClient() throws Exception {
assertNotNull(client);
}
The bar is green, but it makes the code either brittle or slow depending on the timeout: if too big the tests are slow, if too small the tests can fail, and it probably depends on the hardware, network, setup… waitForWarmup is not making the difference since it works once the CouchbaseClient is created.
How about trying a few times until it succeeds?
@BeforeClass
public static void setUpBefore() throws Exception {
clusterManager = new ClusterManager(Arrays.asList(URI.create(COUCH_SERVER)), admin, adminPass);
clusterManager.createNamedBucket(BucketType.COUCHBASE, TEST_BUCKET, 100, 0, PASSWD, true);
for (int i = 1; i <= 10; i++) {
try {
client = new CouchbaseClient(Arrays.asList(URI.create(COUCH_SERVER)), TEST_BUCKET, PASSWD);
System.out.println("managed to open the client in " + i + " attempts");
break;
} catch (RuntimeException e) {
if (e.getMessage().startsWith("Could not fetch a valid Bucket configuration.")) {
Thread.sleep(100);
} else {
throw e;
}
}
}
}
Green bar again, took 4s, with the message: “managed to open the client in 5 attempts”. I swear 500 was just a lucky guess, you can’t make this shit up 🙂
Lets add one more test to see how Fast this is:
public class TestConn {
static final String adminPass = “*******";
static final String admin = “admin";
static final String TEST_BUCKET = "test1";
static final String PASSWD = "s3cr3t";
static final String COUCH_SERVER = "http://192.168.1.128:8091/pools";
static ClusterManager clusterManager;
CouchbaseClient client;
@BeforeClass
public static void setUpBefore() throws Exception {
clusterManager = new ClusterManager(Arrays.asList(URI.create(COUCH_SERVER)), admin, adminPass);
}
@Before
public void setUp() throws Exception {
clusterManager.createNamedBucket(BucketType.COUCHBASE, TEST_BUCKET, 100, 0, PASSWD, true);
for (int i = 1; i <= 10; i++) {
try {
client = new CouchbaseClient(Arrays.asList(URI.create(COUCH_SERVER)), TEST_BUCKET, PASSWD);
System.out.println("managed to open the client in " + i + " attempts");
break;
} catch (RuntimeException e) {
if (e.getMessage().startsWith("Could not fetch a valid Bucket configuration.")) {
Thread.sleep(100);
} else {
throw e;
}
}
}
}
@After
public void tearDown() throws Exception {
if (client != null) client.shutdown();
client = null;
clusterManager.deleteBucket(TEST_BUCKET);
}
@AfterClass
public static void tearDownAfter() throws Exception {
if (clusterManager != null) clusterManager.shutdown();
}
@Test
public void firstTest() throws Exception {
assertNotNull(client);
}
@Test
public void secondTest() throws Exception {
assertNotNull(client);
}
}
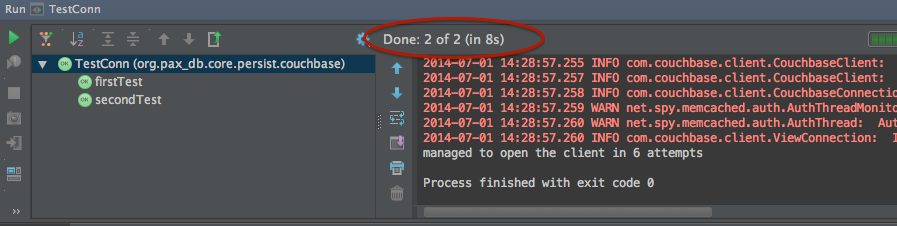
Oops, F just went out of window, it’s super slow, took 8 secs without any ops against the database.
Ok, how about creating bucket once per class and then calling flush/flushBucket to delete all data:
public class TestConn {
static final String adminPass = “********";
static final String admin = "Administrator";
static final String TEST_BUCKET = "test1";
static final String PASSWD = "s3cr3t";
static final String COUCH_SERVER = "http://192.168.1.128:8091/pools";
static ClusterManager clusterManager;
CouchbaseClient client;
@BeforeClass
public static void setUpBefore() throws Exception {
clusterManager = new ClusterManager(Arrays.asList(URI.create(COUCH_SERVER)), admin, adminPass);
clusterManager.createNamedBucket(BucketType.COUCHBASE, TEST_BUCKET, 100, 0, PASSWD, true);
}
@Before
public void setUp() throws Exception {
for (int i = 1; i <= 10; i++) {
try {
client = new CouchbaseClient(Arrays.asList(URI.create(COUCH_SERVER)), TEST_BUCKET, PASSWD);
System.out.println("managed to open the client in " + i + " attempts");
break;
} catch (RuntimeException e) {
if (e.getMessage().startsWith("Could not fetch a valid Bucket configuration.")) {
Thread.sleep(100);
} else {
throw e;
}
}
}
}
@After
public void tearDown() throws Exception {
if (client != null) {
client.flush().get();
client.shutdown();
}
client = null;
}
@AfterClass
public static void tearDownAfter() throws Exception {
clusterManager.deleteBucket(TEST_BUCKET);
if (clusterManager != null) clusterManager.shutdown();
}
@Test
public void firstTest() throws Exception {
assertNotNull(client);
}
@Test
public void secondTest() throws Exception {
assertNotNull(client);
}
}

Nope, now it took almost 30sec (note: clusterManager.flushBucket(TEST_BUCKET) does not make any difference):
Hm, for sure I’m not the first one to try this, let’s see how other are doing this. Let’s see if there’s any github repo that does this: https://github.com/search?q=createNamedBucket&ref=cmdform&type=Code only 3 in java as of the writing this post, none doing unit testing…
Maybe the repos are private… Lets search the forums. There’s this post from Mike, a CouchBase engineer:
I can see that after trying flush you then tried to do the recommended thing and delete and recreate the bucket, but your running into a few issues with runtime exceptions. The only time I have run into this issue is when I have been creating and deleting buckets really fast. For example, when we switched our unit tests off of flush and moved to deleting and recreating buckets we were doing this process many times per second.
By “really fast” Mike obviously means way more than “many times per second”, but I’d happily take even once or twice per second. ViewTest.java used to create buckets once per class, but never used flush:
@BeforeClass
public static void before() throws Exception {
BucketTool bucketTool = new BucketTool();
bucketTool.deleteAllBuckets();
bucketTool.createDefaultBucket(BucketType.COUCHBASE, 256, 0, true);
}
What options do I have now? Instead of creating/deleting buckets or using flush(), think I’ll have to manually delete all items in the bucket. This turned out to be fast enough.
With the test setup in place, let’s spin up that fail/pass/refactor wheel.
CRUD class
I usually start with this test when implementing a CRUD:
@Test
public void test_save_and_load() {
assertEquals("should be empty to start with”,0, repo.count());
repo.save(item);
assertEquals(“failed to save”,1, repo.count());
}
If you object that testing save() using count() isn’t true to TDD’s principles, let’s say I’m just being pragmatic. Can you find a case where this logic fails to catch a bug?
I like to start with an empty table/collection/bucket, run the test, and don’t clean up afterwards, so it’s easy to manually verify if the data is really there.
How do I count number of items in a bucket? countdistinct-keys-using-mapreduce and basic-couchbase-querying-for-sql-people explain.
Have to make a view for that… which means I need to figure out how to test views first. couchbase-101-create-views-mapreduce, couchbase-101-create-views-mapreduce-from-your-java-application.
Boils down to creating a DesignDocument, adding a View and saving the design doc. Sounds simple.
@Test
public void test_create_views() throws Exception {
try {
DesignDocument designDoc = client.getDesignDoc(repo.designDocName);
fail("design doc already exists!? " + designDoc);
} catch (Exception e) {
//no views yet, good
}
repo.createViews();
final View view = client.getView(repo.designDocName, repo.viewName);
assertNotNull(view);
}
Red bar, move on to implement createViews(). As of SDK 1.4 ViewResponse exposes the total number of rows in the view. Since we’ll be storing all kinds of different document (classes, think BlogPost, Comment, …) in a single bucket, views have to make sure they onloy index the intended document types, and emit document ids:
function (doc) {
if (doc.type && doc.type == "org.pax_db.core.DatasetInfo") {
emit(doc.id, null);
}
}
Green bar, lets implement the count() method:
@Override
public long count() {
final View view = client.getView(designDocName, viewName);
Query query = new Query();
query.setIncludeDocs(false);
query.setLimit(1);
query.setStale(Stale.FALSE);
final ViewResponse response = client.query(view, query);
return response.getTotalRows();
}
Run the test again, unexpectedly it fails again in client.query():
Caused by: java.lang.RuntimeException: Failed to access the view
The view exists – client.getView() returns non null object, but query fails. Googling again: http://stackoverflow.com/q/24306216. Ahhh, timing.. I don’t mind async workflows, but async workflow without callbacks, that’s annoying. No answers on the SO question, more googling… new-views-are-immediately-available
The view is created, but then the server needs to index all existing docs and that takes some time, which is funny since here the bucket is empty. Anyhow, it’s not instantaneous, need to wait. Back to looping. Adapting the exponential backoff code sample given at Couchbase+Java+Client+Library (one more interested thing to test). Run the test again and now it passes.
Implementing save()… first JSON encoding (using Gson). Hm, need to add this type file which is not present as a field. StackOverflow proves useful again.
JsonElement json = gson.toJsonTree(item);
json().addProperty("type", item.getClass().getCanonicalName());
hm, this needs testing.
@Test
public void test_gson() throws Exception {
final Gson gson = new GsonBuilder().setPrettyPrinting().create();
final JsonElement el = gson.toJsonTree(item);
el.getAsJsonObject().addProperty("type", item.getClass().getCanonicalName());
final String json = gson.toJson(el);
assertTrue(json, json.contains("id"));
assertTrue(json, json.contains("name"));
assertTrue(json, json.contains(item.getName()));
assertTrue(json, json.contains(item.getDescription()));
...
}
Fails with the description field. Debugger to help: looks like some encoding thing. http://stackoverflow.com/a/11361318/306042: GsonBuilder#disableHtmlEscaping() solved the problem.
Back to save(), need to properly code around future.get(), handle exceptions and thread interrups.. and it works.
Going to the admin console http://192.168.1.128:8091/index.html#sec=buckets, and browsing the test bucket, I can see one document:
{
"id": "1",
"name": "H. sapiens PeptideAtlas Build May 2010",
"organ": "WHOLE_ORGANISM",
"description": "Spectral counting data based on MS/MS data from Human PeptideAtlas Build May 2010
Interaction consistency score: 13.5 Coverage: 40%",
"score": "13.5",
"isIntegrated": false,
"hasPeptideCounts": true,
"type": "org.pax_db.core.DatasetInfo"
}
Conclusion – how much I miss rich query API..
Compared to MongoDB’s collection#save() & collection#count() and rich query API, CouchBase requires more work (including reasoning about getting stale data – Query#setStale(Stale)). Maybe spring-data can help generate CRUD repos, and ElasticSearch for rich query API (until N1QL is ready..).
Hi Milan,
first thanks very much for the honest feedback and spending the time to write a blog post like this. I’m the maintainer of the Java SDK and always looking for stuff like this.
second, we’re aware of the suboptimal flush performance and the maybe tedious process during testing. We’re trying to improve that process in the 2.0 SDKs with more natural flows and observables. (for example the flush in the new SDK creates a marker document, then flushes and then polls until its gone), so not much work to do on your side other than wait until the observable is completed. We’re trying to get to the same behaviour for design document management so it will get easier. In parallel, the server team is looking into decreasing the time it takes for flush and all related components on the server side.
Btw, the BucketTool is still there on the release14 branch (because master is now 2.0 land) and here you can see the warmup check: https://github.com/couchbase/couchbase-java-client/blob/release14/src/test/java/com/couchbase/client/BucketTool.java#L153
If you have anything you’d like to see improved, please raise a ticket on JIRA directly (http://www.couchbase.com/issues/browse/JCBC) and we’ll take it from there.
Thanks again for the post!
Michael
Hey Michael, these are minor issues, I’m sure you’ll eventually fix all of ’em, especially now with the new grant (congrats 😉 keep up the good work, can’t wait to see SDK 2.0 out